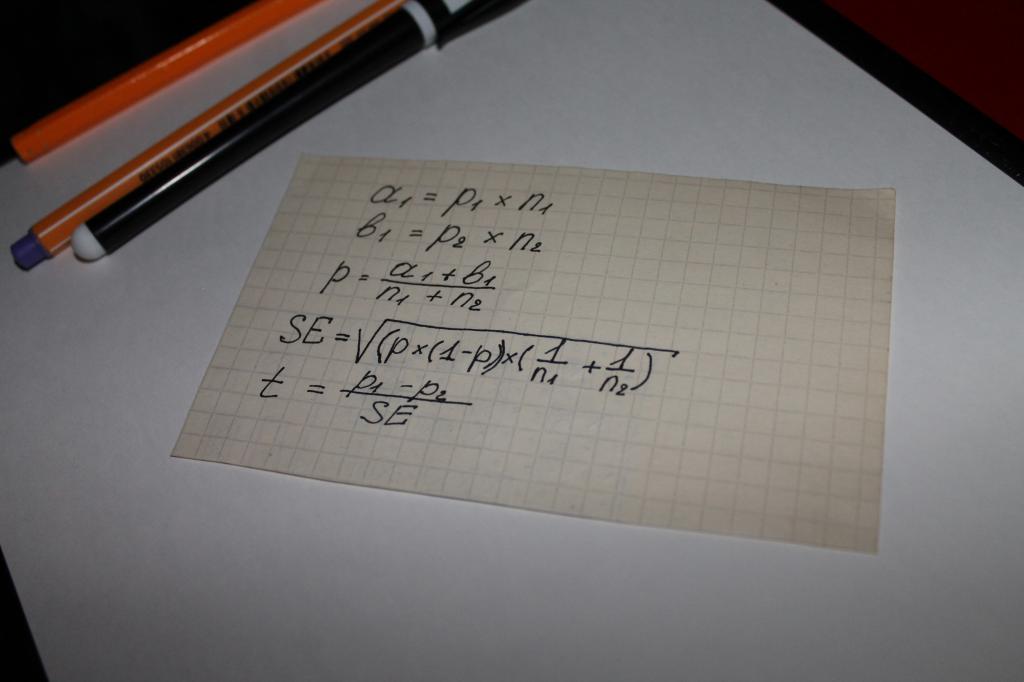
Statistiline tähtsus. Statistiliste uuringute tulemuste usaldusväärsuse hindamine
Katse teaduslikus ja praktilises olukorras võivad teadlased uurida mitte kõiki inimesi (üldine agregaat, elanikkond), vaid ainult teatud valimit. Näiteks isegi kui me uurida suhteliselt väikese grupp inimesi, näiteks kannatusi teatud haiguse, siis sel juhul on väga ebatõenäoline, et meil on asjakohased ressursid või vajadust testida iga patsiendi. Selle asemel testivad nad tavaliselt proovi elanikkonnast, sest see on mugavam ja kulub vähem aega. Sel juhul, kuidas me teame, et saadud tulemused valim esindavad kogu rühma? Või kui kasutate professionaalset terminoloogiat, kas me saame olla kindlad, et meie uuring kirjeldab õigesti kõiki elanikkond, mille valim me kasutasime?
Sellele küsimusele vastamiseks on vaja kindlaks määrata katsetulemuste statistiline tähtsus. Statistiline tähtsus Märkimisväärne tase, lühendatud Sig.), või / 7-taseme tähtsus (P-tase) -see on tõenäosus, et see tulemus Õigesti esindab elanikkonda, mille valim uuriti. Pange tähele, et see on ainult tõenäosus - See on võimatu absoluutse garantiiga väita, et see uuring Õigesti kirjeldab kogu elanikkonda. Parimal juhul võib tähendus, võite järeldada, et see on väga tõenäoline. Seega järgmine küsimus paratamatult langeb: milline peaks olema tähtsuse tase, et see tulemus võib pidada õige iseloomuliku elanikkonna?
Näiteks, millist tõenäosust olete valmis ütlema, et sellised võimalused on piisavad riskiks? Kui võimalused on 10 100-st või 50-st 100-st? Ja mis siis, kui see tõenäosus on suurem? Mida võib öelda selliste võimaluste pärast 100-st 100-st 95-st 100-st või 98-st? Riskiga seotud olukorra jaoks on see valik üsna problemaatiline, sest see sõltub isiku isikuomadustest.
Psühholoogias uskus see traditsiooniliselt, et 95 või enam võimalust 100 tähendavad, et tulemuste õigsuse tõenäosus on piisavalt kõrge, et jagada kogu elanikkonnale. See arv on loodud teadusliku ja praktilise tegevuse protsessis - ei ole õigust, mille kohaselt see tuleks valida võrdluspunktina (ja tõepoolest teistes teadustes valivad mõnikord olulisuse taseme väärtused).
Psühholoogias kasutavad nad seda tõenäosust mõnevõrra ebatavaline viisil. Selle asemel, et tõenäosus, et valim on populatsioon, on tõenäoline, et proovivõtmine on näidatud ei esinda Elanikkond. Teisisõnu, see on tõenäosus, et avastatud suhted või erinevused on juhuslikud ja ei ole agregaadi vara. Seega, selle asemel, et kinnitada, et uuringu tulemused on õige tõenäosusega 95-st 100-st, ütlevad psühholoogid, et on olemas 5 võimalust 100, et tulemused on valed (samal viisil 40 võimalust 100 kasuks) Tulemuste õigsus tähendab 60 võimalust 100 kasuks nende ebaõnne). Tõenäosuste väärtust väljendatakse mõnikord protsendina, kuid see on sageli kirjutatud kujul kümnendad fraktsioonid. Näiteks 10 tõenäosust 100 on esindatud kujul kümnendfraktsioon 0,1; 5 100-st salvestatakse 0,05-ni; 1 100 - 0,01. Sellise salvestamise vormiga on piir väärtus 0,05. Et tulemus peeti õigeks, selle tähtsuse tase peaks olema allpool See number (mäletate, et see on tõenäosus, et tulemus vale kirjeldab populatsiooni). Lõpetada terminoloogia, lisage, et "tõenäosus ebaõigsuse tulemuseks" (mis on õigem helistada tähtsuse tase) tavaliselt tähistatud ladina kirjaga r. Katse tulemuste kirjeldus sisaldab tavaliselt kokkuvõtlikku järeldust, näiteks "tulemused osutusid usaldusväärsuse tasemel märkimisväärseks (R p) alla 0,05 (st vähem kui 5%).
Seega tähtsuse tase ( riba) näitab tõenäosust, et tulemused mitte Esindavad elanikkonda. Psühholoogia traditsioonide kohaselt arvatakse, et tulemused peegeldavad usaldusväärselt üldist pilti, kui väärtus riba Vähem kui 0,05 (st 5%). Sellegipoolest on see ainult tõenäosus, ja mitte üldse tingimusteta tagatis. Mõnel juhul võib see järeldus olla vale. Tegelikult saame arvutada, kui tihti võib juhtuda, kui vaatame tähtsuse taseme väärtust. 0,05 V5 tähenduse tasemel 100 juhtumist on tulemused ilmselt valed. 11A Esimene lühikoht näib olevat liiga tihti, aga kui te sellest mõtlete, siis 5 võimalust 100 on sama kui 20-st 20-st. Teisisõnu, ühes igast 20 juhtumist on tulemus vale. Sellised võimalused ei tundu eriti soodsad ja teadlased peavad komisjoni ettevaatlikult olema esimese liiki vead. Seda nimetatakse viga, mis tekib siis, kui teadlased usuvad, et nad leidsid tegelikke tulemusi ja tegelikult nad ei ole. Vastupidised vead, mis koosnevad asjaolust, et teadlased usuvad, et nad ei leidnud tulemust, kuid tegelikult seda nimetatakse teise varda vead.
Need vead tekivad sellepärast, et ebaõigsuse võimalust ei ole võimalik välistada statistiline analüüs. Vea tõenäosus sõltub tulemuste statistilise tähtsuse tasemest. Oleme juba märkinud, et tulemus on õige, peaks tähtsuse tase olema väiksem kui 0,05. Muidugi mõned tulemused on madalam tase, ja sageli on võimalik täita tulemusi nii madal /?, 0,001 (väärtus 0,001 näitab, et tulemused võivad olla vale tõenäosusega 1000-st). Kui väiksem väärtus P, seda raskem meie usaldus tulemuste õigsuse vastu.
Vahekaardil. 7.2 kujutab endast traditsioonilist tõlgendust tähtsuse taseme tõlgendamise statistilise järelduse võimaluse ja teabe kättesaadavuse kohta (erinevused).
Tabel 7.2.
Psühholoogias kasutatud olulisuse traditsiooniline tõlgendus
Praktiliste uuringute kogemuste põhjal on soovitatav: Kui võimalik vältida esimese ja teise liiki vigu vastutustundlikke järeldusi, tuleks otsused teha erinevuste olemasolu (teatis), keskendudes tasemele riba P-kirju.
Statistiline kriteerium(Statistiline test) - See on vahend statistilise tähtsuse taseme määramiseks. See on otsustav reegel, mis tagab vastuvõtmise tõelise ja kõrvalekalle vale hüpotees kõrge tõenäosusega.
Statistiliste kriteeriumide tähistatakse ka teatud numbri ja väga arvu arvutamise meetodi abil. Kõiki kriteeriume kasutatakse ühe peamine eesmärk: Määrake tähtsuse tase Andmed analüüsitakse nende abiga (s.o tõenäosus, et need andmed kajastavad tõelist mõju, mis õigesti esindab populatsiooni, millest valim moodustub).
Mõningaid kriteeriume saab kasutada ainult tavaliselt jaotatud andmete jaoks (ja kui funktsioon mõõdetakse intervalliga) - neid kriteeriume kutsutakse tavaliselt parameetriline. Muude kriteeriumide abil saate analüüsida peaaegu iga jaotusõiguse andmeid - neid kutsutakse mitteparameetriline.
Parameetrilised kriteeriumid - kriteeriumid, sealhulgas jaotusparameetrid arvutusvalemi, s.o. Keskmine ja dispersioon (^ -criterid stiilis, Fischeri F-kriteerium jne).
Parameetrilised kriteeriumid - kriteeriumid, mis ei sisalda jaotusparameetrite arvutamise valemis ja töösageduste või auastmete põhjal (kriteerium Q. Rosenbauma, kriteerium U. Manna - Whitney
Näiteks, kui me ütleme, et erinevuste täpsus määrati üliõpilase ^ -criteride poolt, tähendab see, et üliõpilane ^ -criterite meetodit kasutati empiirilise väärtuse arvutamiseks, mis seejärel võrreldakse tabeli (kriitilise) väärtusega.
Empiiriliste (arvutatud) ja kriteeriumi kriitiliste väärtuste suhe (tabel), saame otsustada, kas meie hüpotees on kinnitatud või ümberkujundatud. Enamikul juhtudel, et me tunnistame erinevusi on märkimisväärsed, on vaja, et kriteeriumi empiiriline väärtus ületab kriitilise tähtsusega, kuigi on olemas kriteeriumid (näiteks mannal - Whitney kriteerium või allkirjakriteeriumid), milles me peame järgima vastupidine reegel.
Mõningatel juhtudel sisaldab kriteeriumi arvutatud valem uuringu vaatluste arv uuringu all, tähistatud kui p. Erilise tabeli kohaselt määrame kindlaks, milline on erinevuste statistilise tähtsuse tase vastab sellele empiirilisele väärtusele. Enamikul juhtudel võib sama kriteeriumi empiiriline väärtus olla märkimisväärne või ebaoluline, sõltuvalt uuringu vaatluste arvust (\\ t n ) või nn nn vabaduse kraadi arv mis on märgitud kui v. (R\u003e) või AS dF. (mõnikord d).
Teades n Või vabaduse kraadi arvu, me vastavalt spetsiaalsetele tabelitele (nende peamine on esitatud 5. liites), saame määratleda kriteeriumi kriitilised väärtused ja võrrelda saadud empiiriline väärtus nendega. See on tavaliselt kirjutatud nii: "Mis n \u003d 22 Kriteeriumi kriitilised väärtused on kujutatud t st \u003d. 2.07 "või" Millal v. (d.) \u003d 2 kriitilise väärtuse styudent kriteeriumi on \u003d 4.30 ja nn.
Tavaliselt eelistatakse veel parameetrilisi kriteeriume ja järgime seda seisukohta. Arvatakse, et nad on usaldusväärsemad ja nende abiga saate rohkem teavet ja teostada sügavamat analüüsi. Mis puudutab matemaatilise arvutamise keerukust, siis kaob see keerukus arvutiprogrammide kasutamisel (kuid mõned teised ilmuvad siiski üsna ületatud).
- Selles õpikusse ei pea me statistilise tähtsusega probleemi.
- Hüpoteesid (null-ya0 ja alternatiivsed - HJ) ja tehtud statistilised otsused, kuna õpilaste psühholoogid õpivad seda eraldi distsipliini "matemaatika psühholoogias". Lisaks tuleb märkida, et projekteerimisel teadusaruanne (kursuste või kursuste või väitekiriVäljaanded) statistiliste lahenduste statistilised hüpoteesid reeglina ei anta. Tavaliselt kirjeldatakse tulemusena kriteeriumi, vajalikku kirjeldavat statistikat (keskmine, sigma, korrelatsioonikoefitsiendid jne), kriteeriumide empiirilised väärtused, vabaduse aste, tingimata tähtsuse tase. Seejärel sõnastatakse sisuline järeldus testi hüpoteesi suhtes näidustusega (tavaliselt ebavõrdsuse kujul) saavutatud või sellega kaasneva tähtsuse tasemega.
Tasustatud funktsioon. Statistilise tähtsuse funktsioon on saadaval ainult mõnes tariifikavades. Kontrollige, kas see on sisse lülitatud.
Te saate teada, kas erinevate vastajate rühmadest saadud vastustel on statistiliselt olulisi erinevusi uuringu küsimustes. Töötada Surnumonkey statistilise tähtsuse funktsiooniga, mis on vajalik:
- Võimaldamise reegli lisamisel küsimusele lubage statistiline tähtsus teie uuringu küsimusele. Valige vastajarühmad võrdlemiseks, et sorteerida uuringute tulemusi visuaalse võrdluse rühmagruppides.
- Uurige tabeleid andmetega teie uuringu küsimustes, et teha kindlaks statistiliselt oluliste erinevuste olemasolu erinevate vastajate rühmadest saadud vastustes.
Vaata statistilist olulisust
Allpool kirjeldatud toimingute tegemisel saate luua uuringu, mis näitab statistilist olulisust.
1. Lisage uuringule suletud tüüpi küsimused.
Selleks, et näidata statistilist tähtsust tulemuste analüüsi käigus, peate rakendama võrdlemise reeglit teie uuringu mis tahes küsimusele.
Rakenda võrdlusreeglit ja arvutage statistiline tähtsus vastuste korral juhul, kui uuringus kasutate ühte järgmistest küsimustest:
On vaja veenduda, et kavandatavaid vastusvõimalusi saab jagada täieõiguslikuks rühmadeks. Vastuse valikuvõimalused Võrdlusreeglite loomisel valite võrdlemise reegli loomisel kasutatakse andmete korraldamiseks kogu uuringus olevate tabelite korraldamiseks.
2. Koguge vastused
Pärast valimisjärgu koostamise lõpetamist looge koguja selle jaotamiseks. On mitmeid viise.
Sa pead saama iga vastuse eest vähemalt 30 vastust, mida kavatsete oma võrdlusreeglis kasutada statistilise tähtsuse aktiveerimiseks ja vaatamiseks.
Uuringu näide
Sa tahad teada, kas mehed on teie toodetega palju rohkem kui naised rahul.
- Lisage kaks küsimust mitme vastuse valikuga:
Mis on sinu sugu? (mees naine)
Kas olete rahul või rahul meie tootega? (rahul (-nnna), rahulolematud (-nnna)) - Veenduge, et vähemalt 30 vastajat on valinud "mees" vastuse võimaluse küsimusele selles küsimusele, samuti vähemalt 30 vastajat, kes valis nende valdkonna "naissoost".
- Lisage võrdlus reegel küsimusele "Mis on teie põrand?" Ja valige mõlemad vastused nagu teie rühmad.
- Kasutage andmete tabelit allpool küsimuse kaardi "Kas olete rahul või rahul meie toode?" Et teada saada, kas mõni vastus näitab statistiliselt olulist erinevust
Mis on statistiliselt oluline erinevus?
Statistiliselt olulist erinevust tähendab, et statistilise analüüsi abil on loodud olulise erinevuste olemasolu ühe vastajate rühma vastuste vahel ja teise rühma vastused. Statistiline tähtsus tähendab, et saadud arvud on usaldusväärselt erinevad. Sellised teadmised aitavad teil oluliselt andmeid andmete analüüsimisel. Sellegipoolest määrab teie poolt saadud tulemuste tähtsus teie poolt. Te peate otsustama, kuidas uuringute tulemusi tõlgendada ja milliseid meetmeid tuleks nende vastu võtta.
Näiteks saad naissoost ostjatelt rohkem nõudeid kui meeste ostjatelt. Kuidas teha kindlaks, kas selline erinevus on reaalne ja kas selles osas tegutseda? Üks suurepäraseid viise oma tähelepanekute kontrollimiseks on uuring, mis näitab teile, kas teie kaubad on meeste ostjatega enamasti rahul. Statistilise valemi abil annab meile pakutud statistilise tähtsuse funktsioon võimaluse kindlaks teha, kas teie toode on tõesti palju nagu mehed kui naised. See võimaldab teil tegutseda faktide põhjal ja mitte arvata.
Statistiliselt olulist erinevust
Kui teie saadud tulemused on esitatud andmete tabelis, tähendab see, et kaks vastajate rühma erinevad üksteisest oluliselt. Termin "märkimisväärselt" ei tähenda, et saadud arvnäitajad on teatud olulised või tähenduses, kuid ainult asjaolu, et nende vahel on statistiline erinevus.
Statistiliselt oluliste erinevuste puudumine
Kui saadud tulemused ei eraldata asjaomases andmeside tabelis, tähendab see, et vaatamata võimalikule erinevusele kahes võrdlusesse ei ole nende vahel statistilist erinevust.
Vastused ilma statistiliselt oluliste erinevusteta näitavad, et proovide suurusega kahe võrreldava elemendi vahel ei tähenda olulist erinevust, kuid see ei tähenda tingimata, et nad ei ole oluline. Võib-olla suurendades proovi suurust, saate tuvastada statistiliselt olulise erinevuse.
Proovivõtu maht
Kui teil on väga väike proovivõtu maht, on märkimisväärsed vaid väga suured erinevused kahe rühma vahel. Kui teil on väga suur valimi suurus, võetakse nii väikesed kui ka suured erinevused oluliseks.
Siiski, kui kaks numbrit on statistiliselt erinevad, ei tähenda see, et tulemuste vahe on teie jaoks praktiline väärtus. Te peate otsustama, millised erinevused teie uuringu jaoks on olulised.
Statistilise tähtsuse arvutamine
Arvutame statistilise tähtsuse, kasutades standardset usaldust 95%. Kui vastus kuvatakse statistiliselt oluliseks, tähendab see seda, et ainult õnnetuse tõttu või proovi vea tõttu esineb kahe rühma erinevus tõenäosusega alla 5% (sageli ilmub: P<0,05).
Statistiliselt oluliste erinevuste arvutamiseks rühmade vahel kasutame järgmisi valemeid:
|
Parameeter |
Kirjeldus | |
|---|---|---|
| a1 | Esimese rühma osalejate osakaal, kes vastas küsimusele teatud viisil korrutatud selle rühma valimi suurusega. | |
| b1. | Teise rühma osaliste osakaal, kes vastab küsimusele teatud viisil korrutatud selle rühma valimi suurusega. | |
| Kombineeritud proovi osakaal (p) | Kahe fraktsiooni kombinatsioon mõlemast rühmast. | |
| Standardviga (SE) | Näitaja sellest, kui palju teie osakaal on tegelikust osast erinev. Väiksem tähendus tähendab, et osakaal on tegeliku osakaalu lähedal, olulisem tähendab, et osa on tegelikust osast oluliselt erinev. | |
| Testi statistiline näitaja (t) | Testi statistiline näitaja. Standardhälbe väärtuste arv, millele see väärtus erineb keskmisest väärtusest. | |
| Statistiline tähtsus | Kui katse statistilise näitaja absoluutväärtus ületab 1,96 * standardhälbe keskmisest väärtusest, peetakse seda statistiliselt oluliseks erinevusteks. |
* 1,96 on väärtus, mida kasutatakse 95% usaldusnivoo tasemele, kuna 95% üliõpilase T-jaotusega töödeldavast vahemikust asub 1,96 standardhälve keskmisest väärtusest.
Näide arvutustest
Eespool kasutatava eeskuju jätkamine, saame teada, kas meeste osakaal tõepoolest kinnitab, et nad on teie tootega rahul, palju kõrgem kui naiste protsent.
Oletame 1000 meest ja 1000 naist osales teie uuringus ja uuringu tulemusena selgus, et 70% meestest ja 65% naistest väidavad, et nad on teie kaubaga rahul. Kas näitaja on 70% oluliselt kõrgem kui kiirus 65% -l?
Esitatakse järgmised andmed uuringus kavandatud valemites:
- p1 (% meestest, rahul toode) \u003d 0,7
- p2 (% naistest, toote rahul) \u003d 0,65
- n1 (küsitletud meeste arv) \u003d 1000
- n2 (küsitletud naiste arv) \u003d 1000
Kuna katse statistilise näitaja absoluutväärtus on suurem kui 1,96, tähendab see, et meeste ja naiste vahe on oluline. Võrreldes naistega on suurema osa tõenäosuse osakaaluga mehed teie toodetega rahul.
Statistilise tähtsuse peitmine
Kuidas peita statistilist tähtsust kõigile küsimustele
- Vajutage "alla" noolele vasakpoolse paneeli võrdluse reegel paremale.
- Valige Redigeerimisreeglit.
- Lülitage funktsioon välja Näita statistilist olulisust Lüliti kasutamine.
- vajuta nuppu Rakendama.
Side statistilise tähtsuse ühe küsimuse jaoks on vaja:
- vajuta nuppu Häälestama Selle probleemi diagrammi kohal.
- Avatud vahekaart Näita parameetreid.
- Tühjendage kirje vastas märkeruut Statistiline tähtsus.
- vajuta nuppu Säästa.
Ekraani parameeter aktiveeritakse automaatselt, kui statistilise tähtsuse kuvamine on sisse lülitatud. Kui valite ekraani märkeruut, on ka statistilise tähtsuse kuvamine keelatud.
Võrdluse reegli lisamisel küsimusele lisatakse statistiline tähtsus teie uuringus. Uurige tabeleid andmete kohta oma uuringu küsimustes, et teha kindlaks statistiliselt oluliste erinevuste olemasolu vastuste vastuste erinevate rühmade rühmade.
Statistika on juba ammu olnud lahutamatu osa elust. Inimesed tulevad kõikjal kõikjal. Statistika põhjal tehakse järeldused selle kohta, kus ja millised haigused on ühised, mis on rohkem nõudluse konkreetses piirkonnas või teatud elanikkonna teatud kihi hulgas. Oma ametiasutuste kandidaatide poliitiliste programmide loomisel põhinevad isegi poliitilised programmid. Nad kasutavad ka kauplemisvõrke ostmisel kaupade ostmisel ja tootjad juhinduvad nende andmete põhjal nende ettepanekutega.
Statistika mängib ühiskonnas olulist rolli ja mõjutab iga tema eraldi liiget isegi tühikutes. Näiteks kui tarkvara, enamik inimesi eelistavad tumedaid värve rõivastes konkreetses linnas või piirkonnas, siis leida ere kollase choaki lilleprint kohalikes turustusvõimalusi on äärmiselt raske. Aga millistest väärtustest moodustavad need andmed, millel on selline mõju? Näiteks, mis on "statistiline tähtsus"? Mida täpselt mõistetakse selle määratlusega?
Mis see on?
Statistika nagu teadus arendab erinevate koguste ja mõistete kombinatsioonist. Üks neist on mõiste "statistilise tähtsuse" mõiste. See on muutujate väärtuste nimi, teiste näitajate ilmumise tõenäosus, mis on tühine.
Näiteks 9-st 10-st inimesest kannavad kummist kingad nende jalgade ajal hommikul jalutuskäigu ajal sügisel metsas pärast vihmane öö. Tõenäosus, et mingil hetkel 8 neist töötatakse välja kahade mokassiinide - tühine. Seega on selles konkreetses näites number 9 väärtus, mida nimetatakse "statistilise tähtsusega".
Seega, kui te arendate edasi antud praktilist näidet, ostetakse kinga kauplused suvehooaja kummist saapad suures koguses kui teisel aastal. Seega mõjutab statistilise väärtuse suurus tavalist elu.
Loomulikult ütleme, et viiruste leviku prognoosimisel ütleme, et viiruste prognoosimisel võetakse arvesse suur hulk muutujaid. Kuid statistiliste andmete olulise näitaja määramise sisu on sarnane, olenemata arvutuste keerukusest ja mittepüsiväärtuste arvust.
Kuidas arvutada?
Kasutatakse võrrandi "statistilise tähtsuse" väärtuse arvutamisel. See tähendab, et sel juhul lahendab kõik matemaatika. Lihtsaim arvutamise võimalus on matemaatiliste toimingute ahel, milles osalevad järgmised parameetrid:
- näiteks kahe liiki tulemused või objektiivsete andmete uurimine, näiteks summad, mille puhul ostud on tehtud, tähistavad A ja B;
- mõlema grupi indikaator - N;
- kombineeritud proovi murdosa väärtus - P;
- "Standardviga" mõiste.
Järgmine samm määratakse üldise katseindikaator - t, selle väärtust võrreldakse 1,96 arvuga. 1,96 on keskmistatud väärtus, mis edastab 95% vahemikku vastavalt õpilase T-levitamisele.
See tekitab sageli küsimuse, mida vahe väärtuste N ja lk. See nüanss lihtsalt selgitab näiteks abiga. Oletame, et arvutatakse lojaalsuse statistiline tähtsus toote või meeste ja naiste brändile.
Sellisel juhul on püüdlused järgmised:
- n - vastajate arv;
- p - rahuloleva toote arv.
Sellisel juhul küsitletud naiste arv märgitakse N1-ni. Seega mehed - N2. Samal väärtusel on P-sümbolis numbrid "1" ja "2".
Testnäidiku võrdlemine üliõpilase arvutatud tabelite keskmistatud väärtustega ja nimetatakse statistiliseks tähendusteks.
Mis mõistetakse testimisega?
Matemaatilise arvutuse tulemusi saab alati kontrollida, seda õpetatakse lastele isegi esmastes klassides. On loogiline eeldada, et statistilised näitajad määratakse arvutusringlusega, seejärel kontrollitud.
Statistilise tähtsuse kontrollimine ei ole siiski mitte ainult matemaatika. Statistika käsitles suur hulk muutuvaid väärtusi ja erinevaid tõenäoseid, mis on kaugeltki alati püsivalt. See tähendab, et kui te naasete artikli alguses esitatud näitesse kummijalatsite, siis loogiline konstruktsioon statistiliste andmete, mis pealiskaudsete kaupade ostud kauplustele, võib kahjustada kuiv ja kuuma ilmaga, mis on Ei ole tüüpiline sügisel. Selle nähtuse tulemusena väheneb kummist saapad ostvate inimeste arv ja turustusvõimalused kannatavad kahju. Pakkuda ilm Anomaly matemaatilist valemit muidugi ei suuda. Seda hetke nimetatakse - "Viga".

See on lihtsalt selliste vigade tõenäosus ja arvestab arvutatud olulisuse taset. Sellega seoses võetakse arvesse nii arvutatud näitajaid kui ka vastuvõetud tähtsate taset ning väärtusi, mida tavapäraselt nimetatakse hüpoteesideks.
Mis on tähtsuse tase?
"Tase" mõiste on kaasatud statistilise tähtsuse peamistesse kriteeriumidesse. Seda kasutatakse rakendatud ja praktilises statistikas. See on mingi väärtus, mis võtab arvesse võimalike kõrvalekaldete või vigade tõenäosust.
Tase põhineb viimistletud proovide erinevuste kindlakstegemisel, võimaldab teil luua nende olulisust või vastupidi õnnetust. See kontseptsioon ei ole mitte ainult digitaalseid väärtusi, vaid ka nende omapäraseid dekodente. Nad selgitavad, kuidas hinnata väärtust ja tase ise määratakse keskmistatud indeksiga tulemuste võrdlemise võrra, näitab see erinevuste usaldusväärsuse astet.

Seega on võimalik ette kujutada taseme mõistet lihtsalt - see on lubatud, tõenäoliselt vea või vastuvõetud statistiliste andmete põhjal tehtud järelduste näitaja.
Millist tähtsust kasutatakse?
Statistiline tähtsus tõenäosuste tegurite lubatud viga praktikas tõrjutakse kolmest baastasemest.
Esimene tase on künnis, mille väärtus on 5%. See tähendab, et vea tõenäosus ei ületa olulisuse taset 5%. See tähendab, et statistiliste uuringute andmete põhjal tehtud järelduste laitmatu ja vigade usaldus on 95%.
Teine tase on 1% künnis. Seega tähendab see arv, et statistiliste arvutustega saadud andmed võivad usaldusega 99%.
Kolmas tase - 0,1%. Selle väärtuse tõttu on vea tõenäosus võrdne protsentide osakaaluga, st vigu on praktiliselt välistatud.
Mis on statistika hüpotees?
Vead, kuidas mõiste on jagatud kaheks suunas, mis on seotud nullhüpoteesi vastuvõtmise või kõrvalekaldumisega. Hüpotees on mõiste, mis on peidetud, vastavalt määratlusele, muude andmete või väidete kogumile. See tähendab, et statistilise raamatupidamise objektiga seotud midagi tõenäosusliku jaotuse kirjeldus.

Lihtsate arvutustega hüpoteesid on kaks - null ja alternatiiv. Erinevus nende vahel on see, et nullhüpotees on aluseks statistilise tähtsuse kindlaksmääramisel osalevate proovide põhiliste erinevuste puudumise tõttu ja alternatiiv on selle vastu vastupidine. See tähendab, et alternatiivne hüpotees põhineb nende proovide olulise erinevuse olemasolul.
Millised on vead?
Vigade kui statistika kontseptsioon sõltuvad otseselt tõelise või mõne muu hüpoteesi vastuvõtmisest. Neid saab jagada kaheks juhiks või tüüp:
- esimene tüüp on tingitud null-hüpoteeside vastuvõtmisest, mis osutus valeks;
- teine on tingitud alternatiivide tagajärg.

Esimest tüüpi vigu nimetatakse valepositiivseks ja esineb üsna sageli kõigis valdkondades, kus kasutatakse statistilisi andmeid. Seega nimetatakse teise tüübi vea vale negatiivseks.
Miks ma vajan statistika regressiooni?
Regressiooni statistiline tähtsus on see, et tema abiga saab määrata nii palju kui reaalsus on erinevate sõltuvuste andmemudeli põhjal arvutatud mudel; Võimaldab tuvastada piisavuse või faktorite puudumise raamatupidamise ja järelduste.
Regressiivne väärtus määratakse tulemuste võrdlemisel Fisher tabelites loetletud andmetega. Või dispersioonianalüüsiga. Olulised regressiooninäitajad on keeruliste statistiliste uuringute ja arvutuste korral, kus on kaasatud suur hulk väärtuste muutujaid, juhuslikke andmeid ja tõenäolisi muudatusi.
Tähtsuse statistiline tähtsus või P-tase - kontrolli peamine tulemus
statistiline hüpotees. Tehnilise keele rääkimine on selle saamise tõenäosus
proovi uuringu tulemus tingimusel, et üldiselt tegelikult
agregaat on õige nullstatistika hüpotees - see tähendab, et ühendus ei ole. Teisisõnu, see
tõenäosus, et avastatud ühendus on looduses juhuslik ja ei ole vara
agregaat. See on statistiline tähtsus, et tähendus on R-tase
kommunikatsiooni usaldusväärsuse kvantitatiivne hindamine: Mida vähem see tõenäosus, usaldusväärsem suhtlemine.
Oletame, et kahe selektiivse söötme võrdlemisel saadi taseme väärtus
statistiline tähtsus p \u003d 0,05. See tähendab, et statistilise hüpoteesi kontrollimine umbes
elanikkonna võrdõiguslikkuse keskmine näitas, et kui see on tõsi, siis tõenäosus
avastatud erinevuste juhuslik välimus ei ole üle 5%. Teisisõnu, kui
samast üldisest agregaatist korduvalt eemaldati kaks proovi, seejärel 1-st
20 juhtumit tuvastatakse nende proovide keskmise vahel palju või rohkem vahe.
See tähendab, et on olemas 5% tõenäosus, et tuvastatud erinevused on juhuslikud
iseloomu ja mitte koguväärtuse vara.
Teadusliku hüpoteesi suhtes on statistilise tähtsuse tase kvantitatiivne
tulemuste tulemuste arvutatavate side kättesaadavuse ülevõtmise aste
selektiivne, selle hüpoteesi empiiriline kontrollimine. Mida väiksem on p-taseme väärtus, seda kõrgem
teadusliku hüpoteesi kinnitava uuringu statistiline tähtsus.
On kasulik teada, mis mõjutab olulisuse taset. Tähtsuse tase, muud asjad võrdsed
eespool toodud tingimused (P taseme väärtus on väiksem), kui:
Suhtluse suurus (erinevused) on suurem;
Funktsiooni varieeruvus (märgid) on väiksem;
Proovi suurus (proovid) on suurem.
ÜhepoolneePI Kahepoolsed kriteeriumid olulisuse kontrollimiseks
Kui uuringu eesmärk on tuvastada kahe üldise parameetrite erinevus
agregaadid, mis vastavad erinevatele looduslikele tingimustele (elutingimused, \\ t
teema vanus jne), siis on sageli teada, milline neist parameetritest on suurem ja
mida vähem.
Näiteks, kui olete huvitatud tulemuste varieeruvusest kontrolli ja
eksperimentaalsed rühmad, siis reeglina mingit usaldust dispersioonide erinevuse märk või
tulemuste standardhälbed, millega hinnatakse varieeruvust. Sel juhul
nullhüpotees on see, et dispersioonid on üksteisega võrdsed ja uuringu eesmärk on
tõestada vastupidist, st Dispersioonide vaheliste erinevuste olemasolu. See on lubatud
erinevus võib olla mis tahes märk. Selliseid hüpoteesid nimetatakse kahepoolseks.
Kuid mõnikord on ülesanne tõendada parameetri suurendamist või vähenemist;
näiteks keskmine tulemus katserühma on suurem kui kontrolli. Kus
see ei ole enam lubatud, et erinevus võib olla teine \u200b\u200bmärk. Sellist hüpoteesit nimetatakse
Ühepoolne.
Kahepoolsete hüpoteeside testimiseks mõeldud tähtsuse kriteeriume kutsutakse
Kahepoolne ja ühepoolne - ühekülgne.
Küsimus tekib sellest, milliseid kriteeriume tuleks valida ühel või teisel viisil. Vastus
See küsimus on väljaspool ametlikke statistilisi meetodeid ja täielikult
Sõltub uuringu eesmärkidest. Mitte mingil juhul ei saa ühte või mõnda muud kriteeriumi valida pärast
Eksperimentide andmete analüüsi põhjal, nagu see võib
Põhjustada ebaõigeid järeldusi. Kui katse on lubatud, et erinevus
Parameetrite võrdlemisel võib olla nii positiivne kui ka negatiivne
Mis teie arvates teeb teie "teise poole" eriliseks, mõttekas? Kas see on seotud tema (tema) isiksusega või oma tundetega, mida te selle isiku kogete? Või võib-olla lihtrate asjaoluga, et hüpotees teie sümpaatia võimaluse kohta, sest uuringud näitavad, on tõenäosus alla 5%? Kui te arvate viimast avaldust usaldusväärsete ja seejärel edukatele dating sites ei oleks põhimõtteliselt:
Kui veedate teie saidi teise analüüsi jagamise või muu analüüsi, võib "statistilise tähtsuse" ebaõige arusaamine põhjustada tulemuste ebaõiget tõlgendamist ja seetõttu ekslikke meetmeid konversiooni optimeerimise protsessis. See kehtib tuhandete teiste statistiliste testide kohta iga päev igas olemasolevas tööstuses.
Et välja selgitada, milline on statistiline tähtsus ", on selle mõiste ajaloos vajalik, et teada saada tema tõelist tähendust ja mõista, kuidas see" uus "vana arusaam aitab teil oma uurimistöö tulemusi õigesti tõlgendada.
Natuke ajalugu
Kuigi inimkond kasutab statistikat teatud eesmärkide lahendamiseks paljude sajandite kaasaegse mõistmise statistilise tähtsusega, katsetamise hüpoteeside, randomiseerimise ja isegi katsete disainiga (DOE) hakkas moodustama alles 20. sajandi alguses ja on lahutamatult seotud Sir Ronald Fisheri nimega (Sir Ronald Fisher, 1890-1962):

Ronald Fisher oli evolutsiooniline bioloog ja statistikud, kellel oli eriline kirg arenemise uurimiseks ja loomuliku valiku uurimiseks loomade ja taimede maailma. Tema ülistanud karjääri ajal töötas ta välja ja populargas palju kasulikke statistilisi vahendeid, mida me ikka veel kasutame.
Fisher kasutas tema poolt välja töötatud meetodeid, et selgitada selliseid protsesse bioloogiana domineerimis-, mutatsioonide ja geneetiliste kõrvalekalletena. Saame rakendada sama tööriistu täna optimeerida ja parandada sisu veebiressursside. Asjaolu, et need analüüsi vahendid võivad osaleda objektidega töötamiseks, mis nende loomise ajal isegi ei eksisteeri, tundub üsna hämmastav. See on sama üllatav, et enne kõige raskemaid arvutusi viidi inimesed läbi ilma kalkulaatoriteta või arvutiteta.
Statistilise eksperimendi tulemuste kirjeldamiseks, millel on suur tõenäosus olla tõde, kasutas Fisher sõna "tähendus" (inglise keele tähtsusest).
Ka üks huvitavamaid arendusi Fisher saab nimetada hüpotees "seksuaalse poja". Selle teooria kohaselt eelistavad naised seksuaalsuhetes loetamatutel meestel eelistada meestele, sest see võimaldab nendel meestel sündinud poegadel olla sama eelsoodumus ja muuta maailma rohkem oma järglastele (me pöörame tähelepanu sellele, et see on just see teooria).
Aga keegi, isegi geniaalne teadlased ei ole vigade eest kindlustatud. Firefish Files tüübitse spetsialistid sellele päevale. Kuid pidage meeles Albert Einsteini sõnad: "Kes igaüks ei ole kunagi eksinud, ei loo ta midagi uut."
Enne järgmise elemendi jätkamist, pidage meeles: statistiline tähtsus on olukord, kus tulemuste erinevus testimise läbiviimisel on nii suur, et seda erinevust ei saa seletada juhuslike tegurite mõjuga.
Mis on teie hüpotees?
Et mõista, mida "statistiline tähtsus" tähendab, peate kõigepealt tegelema sellega, mida "testimise hüpoteeside testimine" on, kuna need kaks neist terminist on tihedalt põimunud.
Hüpotees on lihtsalt teooria. Kui te arendate mis tahes teooriat, peate kehtestama menetluse piisava arvu tõendite kogumiseks ja tegelikult nende tõendite kogumiseks. On kahte tüüpi hüpoteesid.

Õunad või apelsinid - mis on parem?
Nullhüpotees
Reeglina on selles kohas paljudel raskusi. Tuleb meeles pidada, et nullhüpotees ei ole midagi, mida peate tõendama, näiteks te tõestate, et saidi teatud muutus toob kaasa konversiooni suurendamise, kuid vastupidi. Nullhüpotees on teooria, mis ütleb, et saidi muudatuste tegemisel ei juhtu midagi. Ja teadlase eesmärk on selle teooria ümber lükata ja mitte tõestada.
Kui te pöördute kuritegude avalikustamise kogemuse poole, kus uurijad ehitavad ka hüpoteesid, kes on kriminaalmenetluse vastu, võtab nullhüpotees tüüp nn süütuse presumptsiooni, mõiste, et süüdistatavat peetakse süütuks, kuni tema süü on olnud tõestatud kohtusse.
Kui nullhüpotees peitub asjaolu, et kaks objekti on oma omadustes võrdsed ja te üritate tõestada, et üks neist on endiselt parem (näiteks parem b), peate loobuma nullhüpoteesist alternatiivse kasuks. Näiteks võrrelda ühe või teise vahendi konversiooni optimeerimiseks. Null hüpoteesil mõlemal on mõlemad sama mõju kokkupuute objektile (või mingit mõju ei ole mõju). Alternatiiv - ühe mõju mõju on parem.
Teie alternatiivne hüpotees võib sisaldada numbrilist väärtust, näiteks B - A\u003e 20%. Sellisel juhul võib nullhüpotees ja alternatiiv võtta järgmine vorm:

Teine alternatiivse hüpoteesi nimi on teadushüpotees, kuna teadlane on alati huvitatud selle konkreetse hüpoteesi tõendamisest.
Statistiline tähtsus ja väärtus "P"
Tagasi tagasi Ronald Fisher ja tema mõiste statistilise tähtsusega.
Nüüd, kui teil on nullhüpotees ja alternatiiv, siis kuidas saate tõestada ühte ja ei tõrjuda teise?
Kuna statistilised andmed selle looduse kohta eeldab teatud komplekti (proovi) uurimist, ei saa kunagi saada 100% kindel tulemustest. Visual Näide: Sageli suunatakse valimistulemused esialgsete küsitluste tulemustega ja isegi põnevusega.
Dr Fisher tahtis luua determinant (eraldusjoon), kes võimaldaks mõista, kas teie katse oli silmitsi või mitte. Nii ilmus usaldusväärsuse indeks. Usaldusväärsus on tase, mida me aktsepteerime, et öelda, et me kaalume "olulist" ja mis ei ole. Kui "P" on usaldusväärsuse indeks 0,05 või vähem, on tulemused usaldusväärsed.
Ära muretse, tegelikult ei ole kõik nii segaduses, nagu tundub.

Gausside tõenäosuste jaotus. Servad - muutuja vähem tõenäoline väärtus, keskel - kõige tõenäolisem. P-indikaator (purustatud roheline ala) on juhuslikult esineva täheldatud tulemuse tõenäosus.
Tavapärase jaotuse tõenäosuste (Gauss jaotus) on esindatus kõigi võimalike väärtuste teatud muutuja graafiku (joonisel eespool) ja nende sageduste. Kui veedate oma uurimistööd õigesti ja asetate seejärel kõik diagrammi vastu võetud vastused, saate lihtsalt sellise jaotuse. Normaalse jaotuse kohaselt saate suure protsendi sarnaseid vastuseid ja ülejäänud valikuvõimalused levivad graafiku servades (nn "sabad"). See koguste jaotus leidub sageli looduses, nii et seda nimetatakse "normaalseks".
Võrrandi kasutamine teie proovide võtmise ja katsetulemuste põhjal saate arvutada, mida nimetatakse "testistatistika", mis näitab, kuidas saadud tulemused tagasi lükatud. See ütleb ka mulle, kui lähedal olete nullhüpotees ustav.
Selleks, et teie pea saavutada, kasutage statistilise tähtsuse arvutamiseks online kalkulaatoreid:

Üks näide selliste kalkulaatorite
Täht "P" näitab tõenäosust, et nullhüpotees on õige. Kui number on väike, näitab see katserühmade vahe, samas kui nullhüpotees järeldab, et nad on samad. Graafiliselt näeb see välja nii, et teie katsestatistika oleks lähemal ühele oma kellakujulise jaotuse sabale.
Dr Fisher otsustas luua künnise tulemuste usaldusväärsuse kohta tasemel p ≤ 0,05. Kuid see väide on vastuoluline, sest see toob kaasa kaks raskusi:
1. Esiteks, asjaolu, et olete tõestanud nullhüpoteeside ebaõnnestumist, ei tähenda, et olete tõestanud alternatiivset hüpoteesit. Kõik see tähtsus tähendab ainult seda, et te ei saa tõestada ei A ega B.
2. Teiseks, kui p indikaator on võrdne 0,049-ga, tähendab see, et nullhüpotees tõenäosus on 4,9%. See võib tähendada, et samal ajal saab teie testide tulemusi olla samaaegselt usaldusväärne ja ekslik.
Võite kasutada P-indikaatorit, kuid saate sellest keelduda, kuid siis peate arvutama võimaluse arvutada nullhüpotees iga üksikjuhtumi tõenäosus ja otsustada, kas see on piisavalt suur, et te ei tee teie kavandatavaid ja testitud muudatusi.
Statistilise testi kõige tavalisem stsenaarium on tähenduse p ≤ 0,05 künnise kehtestamine enne katse käivitamist. Lihtsalt ärge unustage tulemuste kontrollimisel hoolikalt uurida p-väärtust.
Vead 1 ja 2
Seal oli nii palju aega, et vigu, mis võivad esineda statistilise tähtsuse näitaja kasutamisel, sain oma nimesid isegi oma nimesid.
Viga 1 (tüüp 1 vead)
Nagu eespool mainitud, on p-väärtus, mis on võrdne 0,05-ga: tõenäosus, et nullhüpotees on ustav, võrdub 5%. Kui te keeldute sellest, te teete numbrile vea 1. Tulemused ütlevad, et teie uus veebisait on konversiooninäitajate suurendanud, kuid on 5% tõenäosus, et see ei ole.
Viga 2 (2. tüüpi vead)
See viga on vastupidine viga 1: Te võtate nullhüpotees, samas kui see on vale. Näiteks testitulemused ütlevad teile, et saidile tehtud muudatused ei toonud parandusi, samas kui muudatused olid. Selle tulemusena: te unustate võimaluse suurendada oma näitajaid.
See viga jagatakse katsetes, millel on ebapiisav valimi suurus, nii et pidage meeles: rohkem proovi, seda kallim tulemus.
Järeldus
Võib-olla ei ole teadlaste seas nii populaarne statistilise tähtsusega. Kui katsetulemused ei ole statistiliselt olulised, on tagajärjed kõige erinevamad: konversiooninäitaja kasvust ettevõtte kokkuvarisemiseni.
Ja kui turundajad kasutavad seda terminit oma ressursside optimeerimisel, peate teadma, mida see tähendab tegelikult. Testimise tingimused võivad erineda, kuid proovi suurus ja edukriteerium on alati oluline. Mäleta seda.